A few weeks ago we wrote about how we use AI alongside Trading Blox — what it does well, what it doesn’t, and the workflow we run. The single biggest risk we flagged was overfitting — specifically, the way AI overfitting in trading systems quietly destroys live performance after pretty backtests. That deserves its own post, because the rest of the systematic trading world has been busy generating thousands of AI-assisted strategies, and the survivorship math is brutal.
Here’s the uncomfortable truth: AI hasn’t reduced the overfitting problem in systematic trading. It has made it worse. The temptation to keep iterating until a backtest looks pretty is no longer constrained by human patience. We’ve all done in twenty minutes what used to take a quant team a week. That’s a great way to write more code; it’s a terrible way to make money.
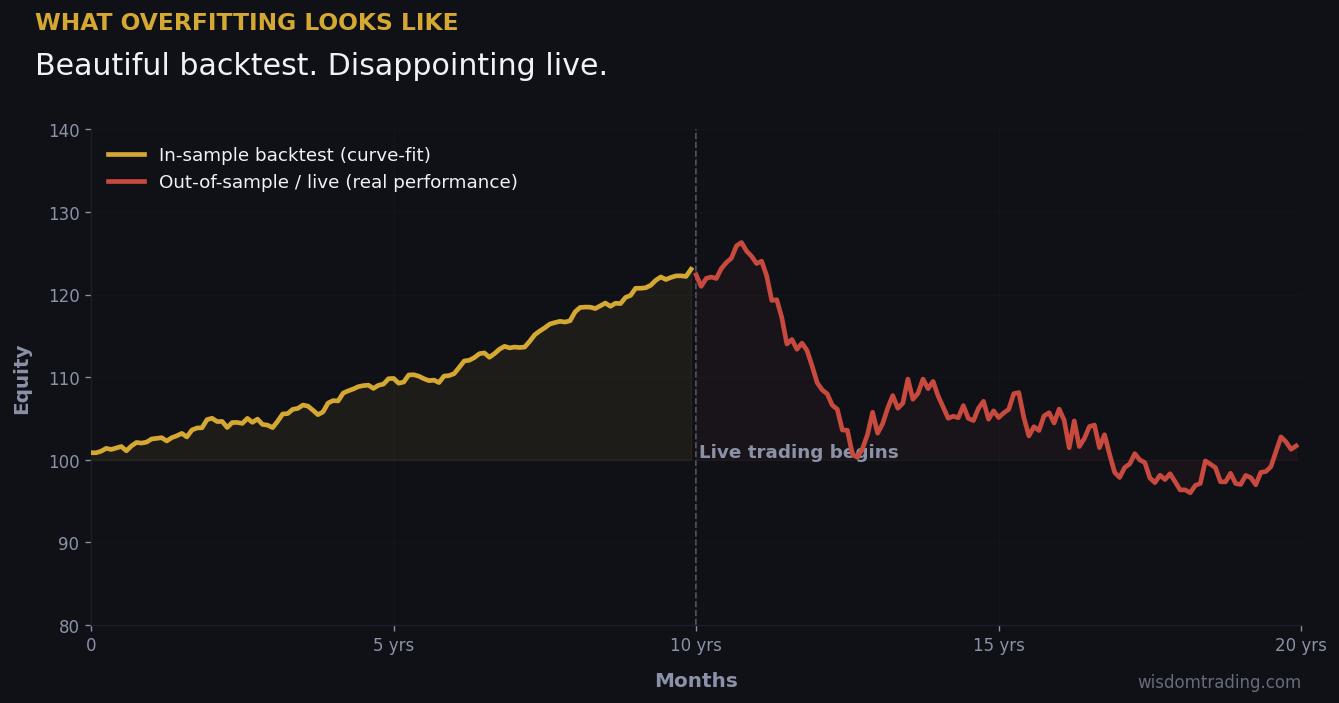
What Overfitting Actually Means
In plain English: an overfit model memorizes its training data instead of learning a generalizable rule. In trading, the training data is a historical price series. The strategy looks at that series, finds patterns, and turns them into rules. If the rules are tuned tightly enough to the specific quirks of that particular history, the strategy will print money on the backtest — and lose money the day you give it real capital.
The reason overfitting is so seductive in systematic trading is that the same data window serves as both the playground and the scoreboard. You build a strategy on the same prices you grade it on. Every “improvement” you make to the rules is implicitly informed by the data you’re testing against. You’re not discovering an edge; you’re describing what already happened.
The honest test — the only one that matters — is whether the strategy works on data the system never saw during development. That’s it. Everything else is, at best, a useful sanity check; at worst, a story you tell yourself.
Why AI Overfitting in Trading Systems Is Worse Than Ever
The common assumption is that AI helps catch overfitting, the way it catches off-by-one errors or look-ahead bias. That’s true in some narrow ways. But the broader effect on the development cycle has been the opposite.
A few mechanisms.
Volume Outpaces Judgment
A human quant generates maybe two or three serious strategy variants per day. An LLM generates twenty in an hour. When you’re running twenty variants, the probability that one of them looks impressive by random chance — not because it has real edge, but because it happened to win the noise lottery — is much higher. The Bonferroni problem gets worse, fast. Each additional variant lowers the bar for “this looks good,” and most users don’t apply the statistical correction that says so.
The Sharpe-Optimization Spiral
It’s tempting to feed a draft strategy back to an LLM and say “make it better.” The model will. It’ll tune lookback windows, add filters, adjust position sizing — all things that improve the in-sample backtest. Each iteration looks like progress. None of it is. By round five, you’ve curve-fit five times and the model has no idea, because the model wasn’t told to care. There’s no friction. No fatigue. No skepticism. Just whatever you optimize for.
Quiet Look-Ahead Bias
This is the one we see catch experienced developers off guard. AI sometimes writes BloxBasic that smuggles future information into a current decision — calculating position size from a close-of-bar price and acting on it within the same bar, using a high or low that wouldn’t have been known at the entry signal, applying a filter built on a moving average that includes today. The backtest looks beautiful. Live trading is a disaster. A careful code review catches most of it. A hurried one doesn’t.
Regime Fit
This is the failure mode that hides the longest. A strategy backtested only on 2014–2019 data — the calmest, lowest-vol stretch of modern equity markets — looks fantastic. It would also have been destroyed in March 2020 and again in 2022. AI can write code that fits any regime you train it on. It cannot tell you whether the regime you trained on still applies. That’s a market-experience judgment, not a code judgment.
Three AI Overfitting Patterns We See in Trading Systems
Across the trader-developed strategies we look at as a broker, the same three patterns of AI overfitting in trading systems produce most of the in-live disappointment.
The first is Sharpe over-optimization. Repeated iteration pushes a strategy with a 1.2 Sharpe to a 2.4 backtest Sharpe and a 0.4 live Sharpe. Every tweak made the historical curve smoother. None of them survived in real markets.
The second is portfolio masking. A strategy that loses money in 18 of 20 markets looks profitable in aggregate because one market — coffee in 2012, or natural gas in 2021 — went vertical. Trading Blox makes this obvious if you look at attribution. If you don’t look, the backtest tells you the strategy works.
The third is clean-data fit. The historical futures data driving the backtest comes roll-adjusted, gap-cleaned, and survivorship-corrected. Live execution gets the messy version: actual fills at actual contract roll dates, holiday-thin liquidity, slippage on the open, weekend gaps. A strategy that depends on precise entries in roll periods or low-liquidity hours often disintegrates between backtest and live.
What Real Out-of-Sample Discipline Looks Like
There’s no clever trick here. The discipline is unglamorous, and it works.
You declare an out-of-sample period before any iteration begins — not after. You define exactly what the test is and what would constitute failure. You then iterate as much as you want on the in-sample data, with whatever AI help you find useful. When you think you have a strategy, you run it once on the out-of-sample period. Once. Whatever happens is the result.
If the strategy survives, you walk forward. You run it on small live capital. You watch fills, slippage, and behavior under stress. You measure live performance against backtested performance with brutal honesty. If live is meaningfully worse than out-of-sample, you stop. The strategy isn’t real.
Trading Blox handles walk-forward natively. The discipline isn’t a tooling problem; it’s a willpower problem. The tooling exists. People skip it because the answers aren’t always what they want to hear.
How We Guard Against AI Overfitting in Trading Systems
Our own process has three rules around AI-assisted development. None of them are technical.
The out-of-sample period is locked before AI sees the data. A strategy gets a fixed budget of iteration cycles — five rounds, then stop. If it isn’t compelling by round five, it isn’t compelling. And every backtest gets attribution by market and by year. If one market or one twelve-month window is doing all the work, the strategy goes in the rejection pile regardless of headline Sharpe.
We’re a broker, so we see the downstream of what other people build. The strategies that survive into year three look nothing like the ones that produced the best backtests. The ones with the best backtests are usually the most overfit; the ones that work in live markets are usually the ones whose developers were most paranoid about overfitting.
What This Means for Investors
If you’re allocating to a manager who uses AI in their development process — and increasingly, that’s most of them — the questions to ask are simple, and they reveal a lot.
What out-of-sample period did the strategy survive? Was the period declared before iteration started? How many iteration cycles ran before the final version? What’s the live track record, and how does it compare to the backtest? If the answers are vague, walk away.
AI overfitting in trading systems isn’t a tooling problem; it’s a discipline problem. We’ve been clearing systematic capital since 2003, through every regime the AI hasn’t seen yet. If you’re evaluating an AI-assisted system and you want a sober second opinion — or you’re a builder who wants execution from a broker who actually reads the code before clearing the first trade — start a conversation or explore our trading-systems services.